Абстрактный
Языковое разнообразие является ключевым аспектом разнообразия человеческого населения и во многом определяет нашу социальную и когнитивную жизнь. В значительной степени распространение этого разнообразия определяется факторами окружающей среды, такими как климат или доступ к побережью. Остается нерешенным вопрос, остаются ли соответствующие факторы постоянными с течением времени. Здесь мы рассматриваем этот вопрос в глобальном масштабе. Мы аппроксимируем разницу между популяциями до и после неолита как разницу между современными охотниками-собирателями и популяциями, занимающимися производством пищи. Используя новый геостатистический подход к оценке плотности языков и языковых семей, мы показываем, что факторы окружающей среды — в основном климатические факторы — значительно сильнее влияют на языковую плотность населения, производящего пищу, чем языковая плотность популяций охотников-собирателей. Имеющиеся данные свидетельствуют о том, что динамика популяции современных охотников-собирателей очень похожа на ту, которую можно реконструировать по палеолитическим записям. Исходя из этого, мы делаем осторожный вывод, что влияние факторов окружающей среды на языковую плотность претерпело существенные изменения с переходом к сельскому хозяйству. После этого перехода влияние окружающей среды на языковое разнообразие населения, производящего пищу, оставалось относительно стабильным, поскольку оно также может быть обнаружено — хотя и в несколько более слабой форме — в моделях, которые фиксируют сокращение языкового разнообразия во время крупномасштабного распространения языков в Средней Азии. голоцен.
1. Введение
Одним из наиболее поразительных аспектов популяционного разнообразия у людей является языковой. Языки делят нас на отдельные группы с далеко идущими последствиями. Языковые границы, как правило, устанавливают и сигнализируют о групповой идентичности, ограничивают и регулируют обмен и требуют изучения языка на протяжении всей жизни, когда группы находятся в контакте. Масштабы этого лингвистически обусловленного разделения ошеломляют. Текущие оценки выходят далеко за пределы 7000 языков [1]. Источником являются процессы постепенного расщепления культурной эволюции, действующие, как уже отмечал Дарвин, с механизмами, сходными с биологическим видообразованием [2,3]. Многие из самых последних таких процессов — около 8000 лет назад — были реконструированы, и в настоящее время, по оценкам, языки делятся на более чем 400 различных семей общего происхождения [1].
Примечательно, однако, что языковое разнообразие крайне неравномерно по всему миру [4–7]. На рисунке 1 показана географическая плотность языков, на которых говорят или о которых известно, что они говорили в прошлом, до недавних событий глобализации [1]. Карты и анализ расстояний до ближайших соседей (рис. 1) свидетельствуют о значительной пространственной кластеризации как на уровне отдельных языков, так и на уровне языковых семей. В крайних случаях, таких как пустыни или полярные регионы, различия в плотности языка просто отражают различия в человеческом присутствии. Но помимо этого, регионы с одинаковым размером населения могут быть фрагментированы на множество языков с малым ареалом или содержать меньше языков, но с более широким ареалом [8]. Например, Южная и Юго-Восточная Азия имеют одинаковую плотность населения, но в Южной Азии плотность языков ниже, чем в Юго-Восточной Азии (электронный дополнительный материал, S2 и рисунок S1). В целом, язык и плотность населения коррелируют очень слабо (электронный дополнительный материал, рисунок S2).
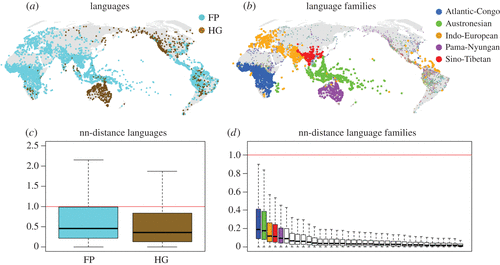
Большинство объяснений географических различий в языковой плотности связывают эффект с биоразнообразием и, следовательно, связывают причины с теми же факторами окружающей среды, которые определяют видовое богатство [9–11]. Биологически более богатая и более сложная среда поддерживает большее количество небольших языковых групп, в то время как менее продуктивная среда требует больших ареалов и более широких сетей обмена для поддержания групп [4,8]. В результате тропические и прибрежные регионы, как правило, содержат большое количество языков ближнего распространения в непосредственной близости, в то время как в более высоких широтах, как правило, встречается меньшее количество языков с более широким распространением.
Нерешенный вопрос заключается в том, остается ли влияние факторов окружающей среды стабильным с течением времени, в частности, было ли оно одинаковым до и после появления сельского хозяйства, скотоводства и многих демографических и культурных изменений, вызванных этими новшествами. Некоторые исследования обнаруживают меньшее влияние факторов окружающей среды на плотность языка у производителей продуктов питания (земледельческих или скотоводческих), чем у популяций охотников-собирателей, потому что постнеолитические технологии, такие как ирригационные системы, могут преодолеть экологические проблемы [12,13]. Напротив, гипотеза экологического риска [6,14] предсказывает большее влияние окружающей среды на языковую плотность среди производящих пищу, чем среди охотников-собирателей, поскольку производство продуктов питания сопряжено со значительными рисками в местных климатических условиях и доступе к воде, в то время как охотники-собиратели популяции собирателей ведут более мобильный и адаптивный образ жизни. Третья возможность, которая мало обсуждалась, основана на наблюдении, что в глобальном масштабе популяции производителей пищи и охотников-собирателей, по-видимому, группируются в разных регионах с лишь ограниченным перекрытием (рис. 1 а). Это распределение может указывать на сценарии дифференциации или смещения ниш. Такие сценарии предсказывают, что воздействие среды в целом остается стабильным, но связано с разной направленностью воздействия (т. е. с разными знаками соответствующих коэффициентов). Например, доступ к пастбищам может положительно привлекать популяции, производящие пищу, одновременно отталкивая популяции охотников-собирателей из тех же районов (и давая отрицательный коэффициент при прогнозировании языковой плотности); и наоборот, доступ к океану может привлечь популяции охотников-собирателей, одновременно отталкивая сельскохозяйственные популяции из тех же районов. Три гипотезы обобщены в таблице 1 вместе с нулевой моделью отсутствия изменений в воздействии окружающей среды на языковую плотность.
Здесь мы проверяем предсказания гипотез в таблице 1 друг против друга. Идеальный тест явно моделировал бы эволюционные процессы при переходе к сельскому хозяйству в большом количестве условий окружающей среды. Однако таких моделей пока не видно, потому что нам не хватает достаточно богатых и непрерывных палеоклиматических оценок и глобальных языковых филогеографий. Существующие языковые филогении ограничены дюжиной семей по всему миру, и их временная глубина остается в основном в пределах неолита [15]. В ответ мы подходим к вопросу через аппроксимацию текущим типом прожиточного минимума. В частности, мы аппроксимируем разницу между до-и пост-сельскохозяйственными условиями, сравнивая факторы языковой плотности в современных популяциях охотников-собирателей (HG) и производителей продуктов питания (FP) (рис. 1a, c). Это приближение подтверждается недавними геномными данными о том, что социальная динамика и структура населения современных охотников-собирателей аналогичны донеолитическим популяциям [16].
Однако эта аппроксимация оспаривается тем фактом, что плотность языков резко сократилась во время распространения нескольких больших семей за последние 8 000 лет, таких как распространение индоевропейского языка в Евразии или пама-нюнганского в Австралии (рис. 1 б). , г). Эти распространения гомогенизировали большие территории в течение некоторого периода времени, прежде чем распространяющиеся языки (например, ранние стадии индоевропейского и пама-нюнганского) диверсифицировались и снова увеличили плотность. Чтобы контролировать эти события, мы следуем более ранним предложениям [4] и оцениваем плотность не только на уровне языков, но и на уровне семей. Оценки на уровне семьи фиксируют снижение плотности, вызванное разбросами. Кроме того, они вводят контроль филогенетической автокорреляции [17], который размещает языки одной семьи в более близком географическом соседстве друг к другу, чем неродственные языки (рис. 1d). Эта автокорреляция потенциально маскирует драйверы языковых дистрибутивов, которые мы стремимся протестировать.
2. Материал и методы
(а) Языковые данные
Мы используем базу данных Glottolog [1], целью которой является исчерпывающий список всех языков, которые служат или служили в качестве регулярных и доминирующих средств общения для людей. Важно отметить, что в базе данных перечислены не только языки, которые используются в настоящее время, но также и языки, которые, как известно, существовали до недавнего времени (или даже менее недавно в тех немногих случаях, когда есть письменные записи). Таким образом, данные приближают языковое разнообразие до массового вымирания языков в последние 100 лет и в настоящее время [9,18]. Glottolog также классифицирует языки по семействам. Как классификация, так и решение о том, что считать отдельным языком, основаны на тщательном и систематическом просмотре опубликованных данных.
Языки представлены в виде координат точек в Glottolog. Площадные представления с более высоким разрешением часто проблематичны, и глобальные лингвистические базы данных обычно избегают их. Во многих случаях соответствующие пространственные формы просто неизвестны. Там, где они известны, языки часто имеют сложные прерывистые распределения в пространстве (например, [19, 20]), что затрудняет анализ на основе полигонов. Однако координаты точек проблематичны для нескольких крупных языков с очень большим распространением, таких как английский, русский или китайский. Здесь Glottolog находит координаты географических или, если известно, исторических центров соответствующих языков. Координаты для английского языка, например, расположены в Восточном Мидлендсе Англии, где современный английский язык уходит своими корнями в пятнадцатый век.
(b) Данные о прожиточном минимуме
Для данных о пропитании мы полагаемся на список из 1205 языков, на которых говорит население HG из недавней компиляции [21], дополненный еще 23 языками из другого источника [22]. Список HG был сопоставлен с названиями языков Glottolog вручную, начиная с доступных наборов совпадений [23]. Поскольку список предназначен для исчерпывания всех известных популяций HG, мы затем связали все языки Glottolog, которых нет в списке, с существованием FP. Возможно, это вызывает некоторую ошибку в недооценке популяций HG, но в настоящее время нет баз данных аналогичного размера, которые позволили бы это исправить. В общей сложности наша база данных содержит 6 672 FP-и 1 251 HG-ассоциированных языков, разделенных на 240 FP-и 247 HG-ассоциированных семейств. Некоторые из этих семей (около 30%) содержат как языки HG, так и язык популяций FP. Однако мы проводим наш анализ отдельно для популяций HG и FP, поэтому двойная классификация не вызывает проблем.
с) экологические данные
Мы включили 10 переменных, которые охватывают различные аспекты природной среды (дополнительную информацию см. в таблице 2 и в электронном дополнительном материале S3). Мы выбрали эти переменные в соответствии с тем, что использовалось в предыдущих исследованиях [7,11,12,14], чтобы обеспечить сопоставимость с более ранними результатами. Следуя недавнему обзору и классификации [7], мы используем шесть «переменных окружающей среды», представляющих климат и растительность.
Для климата [24] мы фокусируемся на осадках, температуре и их производных, таких как количество месяцев со средней температурой выше 15°C (n_теплых_месяцев), что соответствует продолжительности среднего вегетационного периода, представляющего экологическую риск, которому подвергается население [14]. Растительность, как результат климата, аппроксимируется покрытием пастбищ [25]. В качестве «переменных пространственной неоднородности» [7] мы используем расстояние до ближайшего океана, расстояние до ближайшей крупной реки, высоту над уровнем моря и шероховатость поверхности местности (измеряемую как стандартное отклонение высоты в пределах заданного радиуса поиска). В дополнение к этим переменным мы включаем подсчет населения в качестве контроля, поскольку, как отмечалось во введении, ожидается, что малонаселенные районы будут поддерживать меньшее количество языковых групп.
Ключевой проблемой переменных окружающей среды является то, что они могут быть закодированы на нескольких уровнях пространственного разрешения. Выбор здесь может иметь далеко идущие последствия, известные как проблема изменяемой площади [26]. Чтобы контролировать это и зафиксировать неопределенность в пространственном разрешении, мы применяем многомасштабный подход [27] и извлекаем информацию об окружающей среде в трех пространственных масштабах, а именно в локальном, мезо-и макромасштабе (таблица 2). .
Модели на уровне языка фиксируют экологические факторы нынешней плотности, в то время как модели на уровне семьи фиксируют снижение плотности, вызванное доисторическим распространением. Для некоторых переменных в таблице 2, таких как гидрологические и ландшафтные переменные, эта разница во времени незначительна. Напротив, климат, растительность и популяционные переменные изменились со времени распространения и до настоящего времени. Точное время распространения неизвестно для большинства семей, но, учитывая их реконструированный возрастной диапазон 4 000–8 000 лет [15,28], распространение должно было произойти в среднем голоцене. Поэтому для моделей на уровне семейства мы используем проекции среднего голоцена для всех климатических [24] и всех данных о растительности и населении [25].
(г) Методы
Оценки языковой плотности страдают от ряда методологических проблем ([7], электронный дополнительный материал, S4). Мы стремимся решить их (а) путем перехода от подсчетов в растре к подсчетам вблизи точек, которые равномерно распределены на земной сфере, (б) путем оценки наблюдаемой языковой плотности по сравнению с тем, что ожидается при случайной базовой линии, (в) путем включения информацию об окружающей среде в нескольких масштабах разрешения и (d) путем разрешения мультиколлинеарности переменных окружающей среды (см. электронный дополнительный материал, S5).
Сначала мы создаем сферическую сетку точек, которые равномерно распределены так, чтобы расстояния между ближайшими соседями были примерно одинаковыми между всеми точками. Для этого не существует аналитического решения, проблемы, известной как проблема Томсона [29]. В ответ мы используем алгоритмическую аппроксимацию, доступную через функцию RegularCoordinates в пакете Rgeosphere [30]. Мы рассчитываем три однородные сетки точек примерно из 300, 1000 и 3000 точек, представляющих различные пространственные разрешения с учетом геометрии суши. Затем мы подсчитываем количество различных языков и отдельных семей, ближайших к каждой точке сетки (рис. 2a, b; и электронные дополнительные материалы, рисунки S3–S4 и таблица S2 для реальных примеров). Эти подсчеты и все последующие анализы выполняются отдельно для популяций HG и FP и отдельно для каждого разрешения сетки.
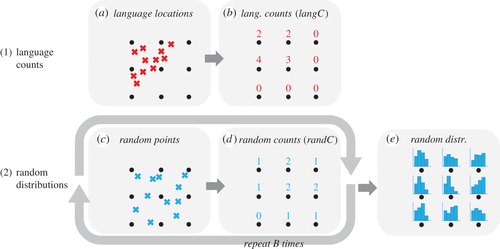
Затем мы сравниваем наблюдаемые подсчеты в каждой точке сетки со случайным исходным уровнем, т. е. с тем, что можно было бы ожидать при случайном распределении языков и языковых семей по суше (исключая океаны и малонаселенные полярные регионы). Для этого мы генерируем случайные языковые местоположения, равные количеству наблюдаемых языков. Мы делаем это с помощью алгоритма randomCoordinates из пакета геосферы [30]. Этот алгоритм решает проблему Томсона путем аппроксимации и обеспечивает равную вероятность местоположений на широтах и долготах. Чтобы вычислить ожидаемое количество для семей, сгенерированные языковые местоположения дополнительно назначаются семейным меткам. Для этого мы генерируем вектор семейных меток с количеством и частотой меток, взятых из данных. Затем мы случайным образом сортируем этот вектор по семействам и линейно присваиваем метки случайным местоположениям вдоль долготы и широты. Это гарантирует, что соседние местоположения имеют более высокую вероятность быть отнесенными к одной и той же семье, сохраняя при этом случайное географическое распределение малых и больших семей. Эта процедура имитирует филогенетическую автокорреляцию в наблюдаемом распределении семейств (рис. 1), обеспечивая сопоставимость между наблюдаемыми и ожидаемыми подсчетами.
Для каждого из B = 500 случайных наборов мы подсчитываем количество местоположений (randC), ближайших к каждой точке сетки (рис. 2c, d), параллельно тому, как мы подсчитываем наблюдаемые языки и семьи. Это дает случайное базовое распределение количества языков и языковых семей в каждой точке сетки (рисунок 2e), непосредственно сопоставимое с наблюдаемыми количествами. В каждой точке сетки мы определяем долю B случайных подсчетов, которые меньше наблюдаемого подсчета. Мы принимаем эту пропорцию как оценку кумулятивной вероятности P (langC) того, что наблюдаемое число превысит то, что ожидается при случайном базовом процессе, т. е. P (langC)=mean (langC > randC) (электронный дополнительный материал, рисунки S5– С 6).
Выбрав подходящий пороговый интервал α, эти кумулятивные вероятности можно оценить относительно того, меньше ли языков, чем ожидалось, при случайном исходном уровне (P (langC) < α), или больше языков, чем ожидалось (P (langC) > α). ). Мы используем термин «впадина» для точек с меньшим количеством языков, чем ожидалось, и «пик» для точек с большим количеством языков, чем ожидалось. Рассмотрим, например, счет 3 на рисунке 2b. Если это количество в основном превышает количество при рандомизации (рис. 2e), оно будет считаться пиковым; если он почти никогда не превышает подсчеты при рандомизации, это будет впадина. Выбор порогового интервала α, за пределами которого счет считается пиком или минимумом, зависит от потребностей подогнанной модели. Мы вернемся к этому ниже, после предоставления более подробной информации о нашей случайной базовой линии и представления нашей стратегии моделирования.
Как отмечалось во введении, на языковую плотность может влиять численность населения. Хотя корреляция слаба за пределами малонаселенных районов (электронный дополнительный материал, S1), мы контролируем возможные искажения двумя способами. Во-первых, мы включаем размер популяции в число предикторов окружающей среды и проверяем его влияние. Во-вторых, мы генерируем второй набор случайных местоположений, который определяется плотностью населения. В частности, мы позволяем вероятности того, что место будет выбрано во время генерации случайных распределений, увеличиваться пропорционально количеству населения в этом месте. Например, густонаселенные регионы, такие как Южная и Юго-Восточная Азия (электронный дополнительный материал, рисунок S1), имеют больше шансов получить случайные местоположения по сравнению с малонаселенными регионами, такими как Австралия или Сибирь. В результате количество языков в соответствии с этим базовым уровнем должно быть выше, чтобы считаться пиковым в густонаселенных регионах, чем в малонаселенных регионах. Это декоркоррелирует наши оценки по распределению человеческого присутствия.
Источник































